One-shot tuner for deep learning compilers (22' CC)
Abs and Intro
Auto-tuning overhead를 줄이기 위해 neural-predictor 접근법을 활용. 해당 pre-trained performance predictor는 auto-tuning process에서 효과적으로 repeated search나 hardware measurements없이 optimized tensor operation codes를 생성하고 cost model update를 제거. Sample-efficient training dataset을 생성하기 위해 task-specific information을 포함하는 input representation 확장. data sampling methods를 high-performing codes를 학습하는 것에 중점을 둠.
optimized tensor programs과 runtime performance 사이의 상관관계를 학습하고 컴파일 중에 high-performing codes를 식별하기 위해 randomly generated code samples를 사용하여 One-shot Tuner을 훈련.
그러나 online adaptation 없이 다양한 유형과 입출력 모양을 가진 unseen tensor operation의 성능 분포를 예측하기 위해 모델을 사전 훈련하는 것은 훈련 데이터와 One-shot tuner를 위한 input representation의 sampling process를 설계하는 데 있어 a unique challenge를 제기.
이 논문에서는 3가지 도전과제를 다룬다. (1) input code representation extended to include explicit task-specific features, (2) a task-sampling mechanism that exploits layer type and size distributions of existing models to improve random sampling efficiency, and (3) an exploration-based code sampling mechanism that enables the predictor model to focus on learning high-performing codes.
Implementation
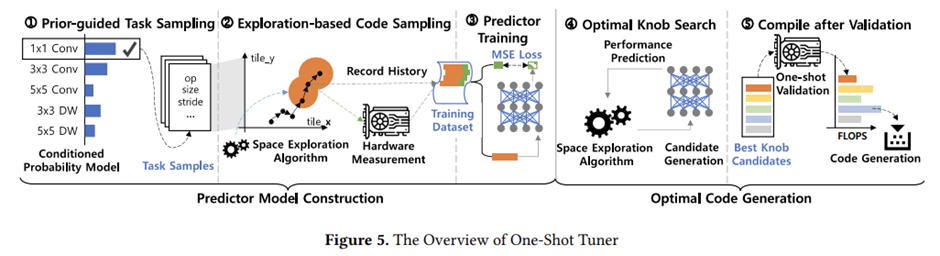
Predictor Model Construction
Predictor model의 accuracy는 training dataset의 quality에 의존. 그러나 실험에 쓰인 데이터의 경우 multiple task에 대한 combined search space는 심하게 skewed distribution을 가짐. 이는 sampling efficiency가 매우 낮기 때문에 간단한 random sampling method을 실현 불가능하게 함. 랜덤 샘플링을 사용하면 신뢰할 수 있는 예측 정확도를 달성하기 위해 비현실적으로 많은 데이터 샘플 필요. 다양한 tasks에서 충분한 representative samples dataset을 활용한 task sampling과 code sampling methods가 이전의 모델 knowledge를 탐색하고 promising samples에 초점을 가짐. sampled code에서 Input features에 의해 생성된 training dataset과 performance은 optimal한 code generation phase를 위해서 pre-train the predictor model를 사용한다.
Prior-Guided Task Sampling
Prior knowledge를 탐색하는 task sampling method를 말한다. 주어진 조건 내에서 발생하는 빈도에 비례하는 수집된 모델의 작업 분포를 조건으로 하는 확률 모델을 구축합니다. 이 PGS 방법은 조건부 확률의 체인에 의해 전체 확률을 추정하는 조건부 확률에 따라 무작위로 훈련 과제를 선택한다. PGS는 predictor가 cornel cases보다 common kernels에 대해 학습을 하기에 practical한 candidates에 대해서 정확도가 높다.
Exploration-Based Code Sampling(EBS)
Performance distribution이 skewed되어있어서 poor-performing한 code가 생긴다. Promising한 code에 대해 학습하기 위해 trajectory of a space exploration algorithm을 제시한다. EBS는 knob search의 convergence를 가속화하고 compiled model performance를 향상시킨다.
Feature Generation
이전 단계의 sampled codes에서 predictor model의 input data로 training시킨다. Unique knob values of each sample determine how a code template is lowered to the loop-level AST, from which TVM generates curve features that represent loop characteristics.
Predictor Model Architecture
DL model architectures와 hyperparameters로 광범위한 연구를 수행하여 높은 정확도로 상관관계를 학습할 수 있는 모델을 찾았다. Multi-head self-attention mechanism은 structured data에서 다차원 상관관계를 이해하는데 효과적이다. 실험했던 model중 수렴 안정성 측면에서 가장 우수.
Optimal Code Generation
모델 구축 단계에 비해 이 단계를 단순하게 유지하고 기존의 많은 TVM 구성 요소를 재사용. 컴파일 중에 auto-tuning back-end는 우선 pre-trained One-Shot Tuner predictor model에 의해 single iteration of space exploration을 수행. knob search에 대해서는 black-box optimizations의 종류인 simulated annealing와 genetic algorithm를 사용하였고 cost model update는 수행되지 않음. 검증 결과는 가장 성능이 좋은 후보를 결정하는 데 사용됩니다. 식별된 knob value값으로 후속 최적화 및 코드 생성을 위해 TVM back-end에 의존. 기존의 auto-tuning과는 달리 knob search와 hardware measurement가 반복 수행되지 않으므로 이 단계는 작업당 수십 초 만에 완료되어 종단 간 컴파일 시간이 크게 단축.